Server
ModelFusion Server is desigend for running multi-modal generative AI flows that take up to several minutes to complete. It provides the following benefits:
- 🔄 Real-time progress updates via custom server-sent events
- 🔒 Type-safety with Zod-schema for inputs/events
- 📦 Efficient handling of dynamically created binary assets (images, audio)
- 📜 Auto-logging for AI model interactions within flows
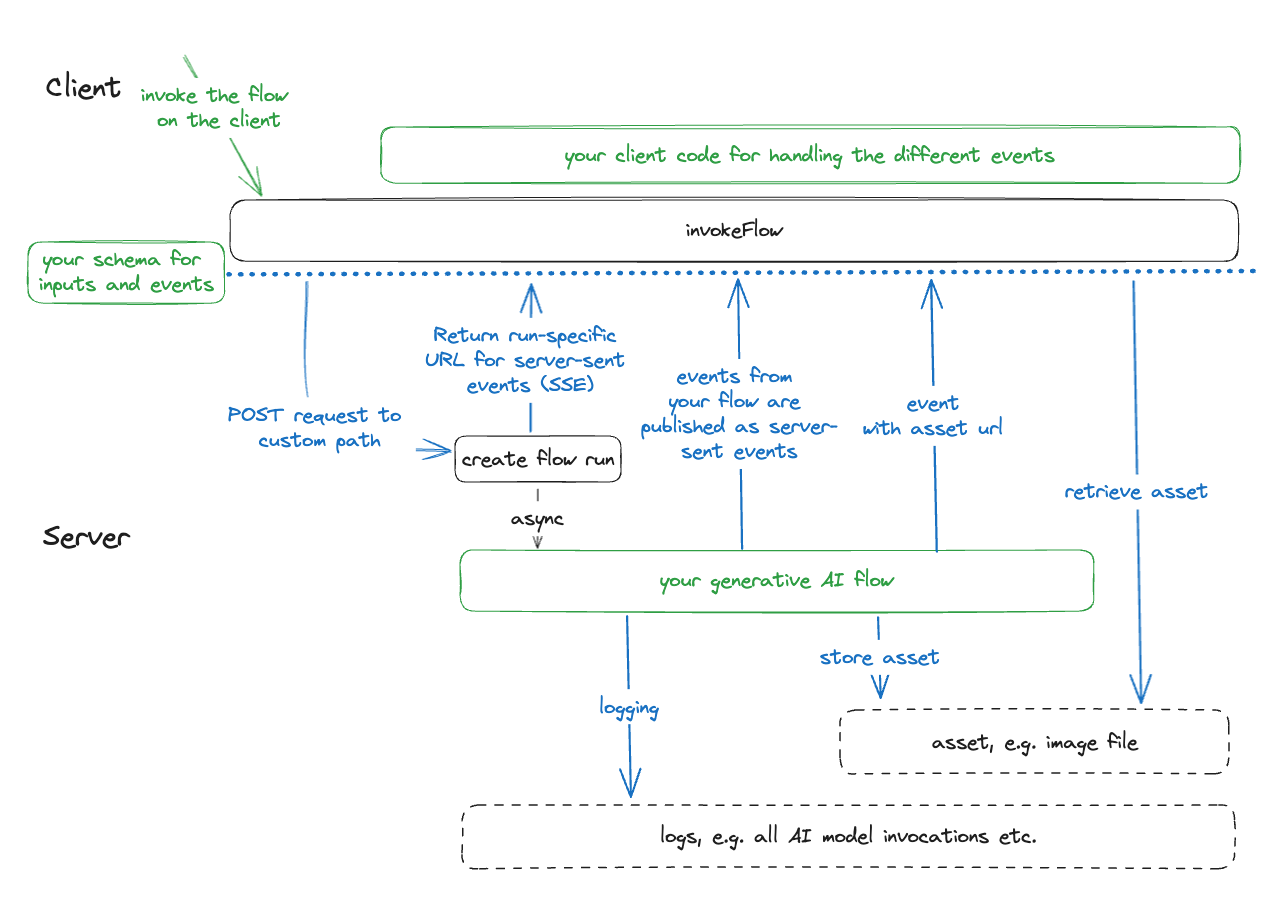
Usage
ModelFusion Server is in its initial development phase and not feature-complete. The API is experimental and breaking changes are likely. Feedback and suggestions are welcome.
Server Setup
ModelFusion Server is currently implemented Fastify plugin.
You can configure the plugin with a logger and asset storage.
Only FileSystemLogger and FileSystemAssetStorage are currently supported, but you can implement your own logger and asset storage and use it with the plugin.
import {
FileSystemAssetStorage,
FileSystemLogger,
modelFusionFastifyPlugin,
} from "modelfusion-experimental/fastify-server"; // '/fastify-server' import path
// configurable logging for all runs using ModelFusion observability:
const logger = new FileSystemLogger({
path: (run) => path.join(fsBasePath, run.runId, "logs"),
});
// configurable storage for large files like images and audio files:
const assetStorage = new FileSystemAssetStorage({
path: (run) => path.join(fsBasePath, run.runId, "assets"),
logger,
});
fastify.register(modelFusionFastifyPlugin, {
baseUrl,
basePath: "/myFlow",
logger,
assetStorage,
flow: exampleFlow,
});
Flow Schema
The flow schema defines the structure of the input and the events of the flow.
export const myFlowSchema = {
// input: Zod schema for the input object
input: z.object({
prompt: z.string(),
}),
// events: Zod schema for the events sent to the client
// (use discriminated unions to distinguish between different event types)
events: z.discriminatedUnion("type", [
z.object({
type: z.literal("text-chunk"),
delta: z.string(),
}),
z.object({
type: z.literal("speech-chunk"),
base64Audio: z.string(),
}),
]),
};
Flow Invocation from the Client
Using invokeFlow, you can easily connect your client to a ModelFusion flow endpoint:
import { invokeFlow } from "modelfusion-experimental/browser"; // '/browser' import path
invokeFlow({
url: `${BASE_URL}/myFlow`,
schema: myFlowSchema,
input: { prompt },
onEvent(event) {
switch (event.type) {
case "my-event": {
// do something with the event
break;
}
// more events...
}
},
onStop() {
// flow finished
},
});
Flow Implementation
ModelFusion flows are composed of a flow schema and an async process function. The process function receives the input object and a flow run. It can use the run to publish events to the client and to store assets.
export const myFlow = new DefaultFlow({
schema: myFlowSchema,
async process({ input, run }) {
// Call some AI model:
const transcription = await generateTranscription({
model: openai.Transcriber({ model: "whisper-1" }),
/* ... */
functionId: "transcribe", // optional: provide functionId for logging
});
run.publishEvent({ type: "my-event", input: transcription });
// more AI model calls and custom processing etc.
},
});
Examples
StoryTeller
multi-modal, object generation, object streaming, image generation, text to speech, speech to text, text generation, embeddings
StoryTeller is an exploratory web application that creates short audio stories for pre-school kids.
Duplex Speech Streaming
Speech Streaming, OpenAI, Elevenlabs streaming, Vite, Fastify, ModelFusion Server
Given a prompt, the server returns both a text and a speech stream response.