Streaming UIs with AI-generated on-demand content can unlock new user experiences.
Until now, most interfaces for dynamic content from large language models (LLMs) were chat interfaces or text autocompletion. With structured outputs, we can now stream complex content and show it incrementally in UI components like lists and tables.
In this tutorial, we will build a travel activity planner with Next.js that uses GPT-4 to generate a list of activities for a given destination and length of stay. The activity list will be streamed to the client and displayed in a React component.
Here is an overview of the tutorial:
- 1. Application Overview - gives an overview of the application
- 2. Project Setup - covers the initial steps to set up a Next.js project
- 3. GPT-4 API Access - explains how to get an OpenAI API key
- 4. Installing Libraries - shows how to install the libraries that are used in the project
- 5. Implementing the Application - guides you through implementing the application
- 6. Running the Application - shows how to run the application
Let's get started.
1. Application Overview
The travel acitivity planner is a simple application that uses GPT-4 to generate a list of activities for a given destination and length of stay. The activity list is streamed to the client and displayed in a React component. Here is a screencast of the final application:

The architecture is pretty straightforward. On the front end, there is a page that contains the inputs and a submit button. It also displays the activity list. The page uses a React hook to call an API route, which in turn calls GPT-4 and streams the activity list to the client:
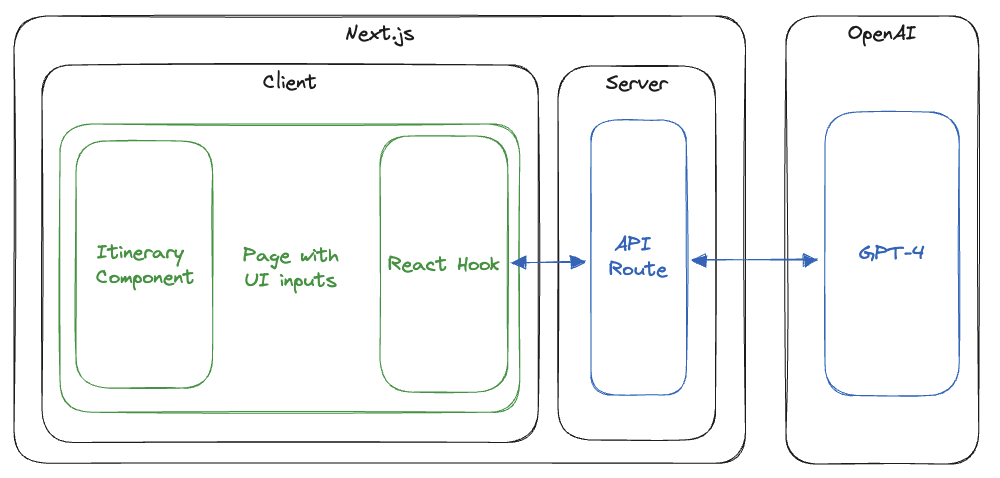
This tutorial will guide you through creating the application. It is split into the following parts:
2. Project Setup (Next.js)
The next step is to create the foundational structure of our Next.js project. Next.js 14 will be used to build our application's frontend and API route.
Here are the steps to create the Next.js project:
-
Execute the following command in your terminal to create a new Next.js project:
npx create-next-app@latest nextjs-openai-object-streaming -
You will be prompted to configure various aspects of your Next.js application. Here are the settings for our project:
Would you like to use TypeScript? Yes
Would you like to use ESLint? Yes
Would you like to use Tailwind CSS? Yes
Would you like to use `src/` directory? Yes
Would you like to use App Router? (recommended) Yes
Would you like to customize the default import alias? NoThese settings enable TypeScript for robust type-checking, ESLint for code quality, and Tailwind CSS for styling. Using the src/ directory and App Router enhances the project structure and routing capabilities.
-
Once the project is initialized, navigate to the project directory:
cd nextjs-openai-object-streaming -
ModelFusion uses
async_hooksin Node.js. This can cause problems with the Next.js compilation of browser assets. To fix this, replace the content ofnext.config.mjswith:/** @type {import('next').NextConfig} */
const nextConfig = {
webpack: (config, { isServer }) => {
if (isServer) {
return config;
}
config.resolve = config.resolve ?? {};
config.resolve.fallback = config.resolve.fallback ?? {};
// async hooks is not available in the browser:
config.resolve.fallback.async_hooks = false;
return config;
},
};
export default nextConfig;
You have successfully created and configured your Next.js project by following these steps. We will later integrate the AI functionalities using OpenAI and ModelFusion. The next part of the tutorial will guide you through installing several libraries that will be used in the project.
You can verify your setup by running npm run dev in your terminal and navigating to http://localhost:3000 in your browser. You should see the default Next.js page.
3. GPT-4 API Access
We will generate JSON with GPT-4 in our application by calling the OpenAI API. You need to sign up for the OpenAI platform and get an OpenAI API key to use GPT-4.
You can then add the API key to your project by creating a file under .env.local with the following content:
OPENAI_API_KEY=<your-api-key>
Next.js automatically loads this file, and the API key is available in the process.env object.
4. Installing Libraries
We will use the following libraries in our project: shadcn/ui, zod, and ModelFusion.
shadcn/ui
shadcn/ui is a UI component library that generates ready-made React components inside your project. It is used to create several UI components for the front end of our application.
shadcn/ui lets you modify the generated components to fit your needs, which is impossible with other UI component libraries such as Material UI.
You can install it and generate the components with the following steps:
-
Setup
shadcn/ui:npx shadcn-ui@latest init -
You will again be prompted to configure various settings. Here is what I used:
Which style would you like to use? Default
Which color would you like to use as base color? Slate
Would you like to use CSS variables for colors? Yes -
We need button, label, and input components. You can generate them with the following commands:
npx shadcn-ui@latest add button
npx shadcn-ui@latest add label
npx shadcn-ui@latest add input
Our UI components ar now ready to be used in our project. Let's install the next library.
Zod
Zod is a TypeScript-first schema validation library. We will use it to define a schema for the data generated by GPT-4. You can add it to the project with the following command:
npm install zod
Zod is great for generating typed JSON from GPT-4, because you can easily convert Zod schemas to JSON schemas using zod-to-json-schema and include descriptions for each property. The JSON schemas are passed to GPT-4 as function definitions or in the prompt (when you are using JSON mode).
ModelFusion
ModelFusion is an AI integration library that I am developing. It enables you to integrate AI models into your JavaScript and TypeScript applications. You can install it with the following command:
npm install modelfusion
With these libraries installed, we are ready to start implementing our application.
5. Implementing The Application
Our application is a simple travel activity planner. You can give it a destination and the length of your stay, and it will generate a list of activities for you to do, grouped by day.
Our implementation will have the following components:
- A schema that defines the structure of the activity list
- An API route that calls GPT-4 and generates the activity list
- A React hook that calls the API route and contains the activity list as a state
- A main page with the UI controls
- An activity list component that displays the (partial) activity list
Let's go through each of these components.
Schema
The iterator schema defines the structure of the activity list. It is also passed into GPT-4 as part of the prompt, either as a function definition or as text.
To define the schema, create a file under src/lib/itinerary-schema.ts with the following content:
import { zodSchema } from "modelfusion";
import { z } from "zod";
export const itinerarySchema = zodSchema(
z.object({
days: z.array(
z.object({
theme: z.string(),
activities: z.array(
z.object({
name: z.string(),
description: z.string(),
duration: z.number(),
})
),
})
),
})
);
export type Itinerary = typeof itinerarySchema._partialType;
The schema is defined using Zod, starting with z.object. It contains an array of days, each of which has a theme and an array of activities. Each activity has a name, description, and duration.
The Zod schema is wrapped with zodSchema to map it to a ModelFusion schema. ModelFusion supports several schema formats, including Zod and unchecked JSON schemas. It also exposes a _partialType property that can be used to define the type of the activity list.
API Route
The API route calls GPT-4 and generates the activity list as a typed JSON object. It then streams the object to the client using the ObjectStreamResponse class.
The API route is necessary to keep your OpenAI API key on the server. This is important to prevent unauthorized access to your API key.
You can setup the route by creating a file under src/app/api/stream-objects/route.ts with the following content:
import { itinerarySchema } from "@/lib/itinerary-schema";
import {
ObjectStreamResponse,
jsonObjectPrompt,
openai,
streamObject,
} from "modelfusion";
export const runtime = "edge";
export async function POST(req: Request) {
const { destination, lengthOfStay } = await req.json();
const objectStream = await streamObject({
model: openai
.ChatTextGenerator({
model: "gpt-4-1106-preview",
maxGenerationTokens: 2500,
})
.asObjectGenerationModel(jsonObjectPrompt.instruction()),
schema: itinerarySchema,
prompt: {
system:
`You help planning travel itineraries. ` +
`Respond to the users' request with a list ` +
`of the best stops to make in their destination.`,
instruction:
`I am planning a trip to ${destination} for ${lengthOfStay} days. ` +
`Please suggest the best tourist activities for me to do.`,
},
});
return new ObjectStreamResponse(objectStream);
}
Let's go through the code in detail. We set up a POST route that is run in the Edge runtime:
export const runtime = "edge";
export async function POST(req: Request) {
// ...
}
The first step is to extract the destination and length of stay from the request body:
const { destination, lengthOfStay } = await req.json();
The main part is calling GPT-4 with the ModelFusion streamObject function:
const objectStream = await streamObject({
model: openai
.ChatTextGenerator({
model: "gpt-4-1106-preview",
maxGenerationTokens: 2500,
})
.asObjectGenerationModel(jsonObjectPrompt.instruction()),
schema: itinerarySchema,
prompt: {
system:
`You help planning travel itineraries. ` +
`Respond to the users' request with a list ` +
`of the best stops to make in their destination.`,
instruction:
`I am planning a trip to ${destination} for ${lengthOfStay} days. ` +
`Please suggest the best tourist activities for me to do.`,
},
});
We call streamObject with GPT-4 turbo (gpt-4-1106-preview) configured as an object generation model. The jsonObjectPrompt.instruction() function uses the OpenAI JSON response format and injects the schema into the prompt.
You can also use function calling (or tool calling) to get JSON output from GPT-3.5 or GPT-4. If you do not have access to GPT-4, check out the ModelFusion generateObject function for more information on function calling with GPT-3.5.
In addition to the model, we also pass the previously defined schema and the prompt. The prompt is the crucial part. We are using an instruction prompt with a system and an instruction part. The system part defines the role of the AI model. In our case, it is a travel itinerary planner. The instruction part defines the user request.
Finally, we return the partial objects as an ObjectStreamResponse (docs), which serializes them for transport to the client:
return new ObjectStreamResponse(objectStream);
We are relying on GPT-4 to know about tourist destinations and activities. This assumption is reasonable for popular destinations because they are likely very well represented in the training set of GPT-4, and we get good answers.
However, the less common a destination is, the more likely it is that GPT-4 will not know about it and hallucinate activities. We can test this by entering a fictional destination like Mars Main Hub.
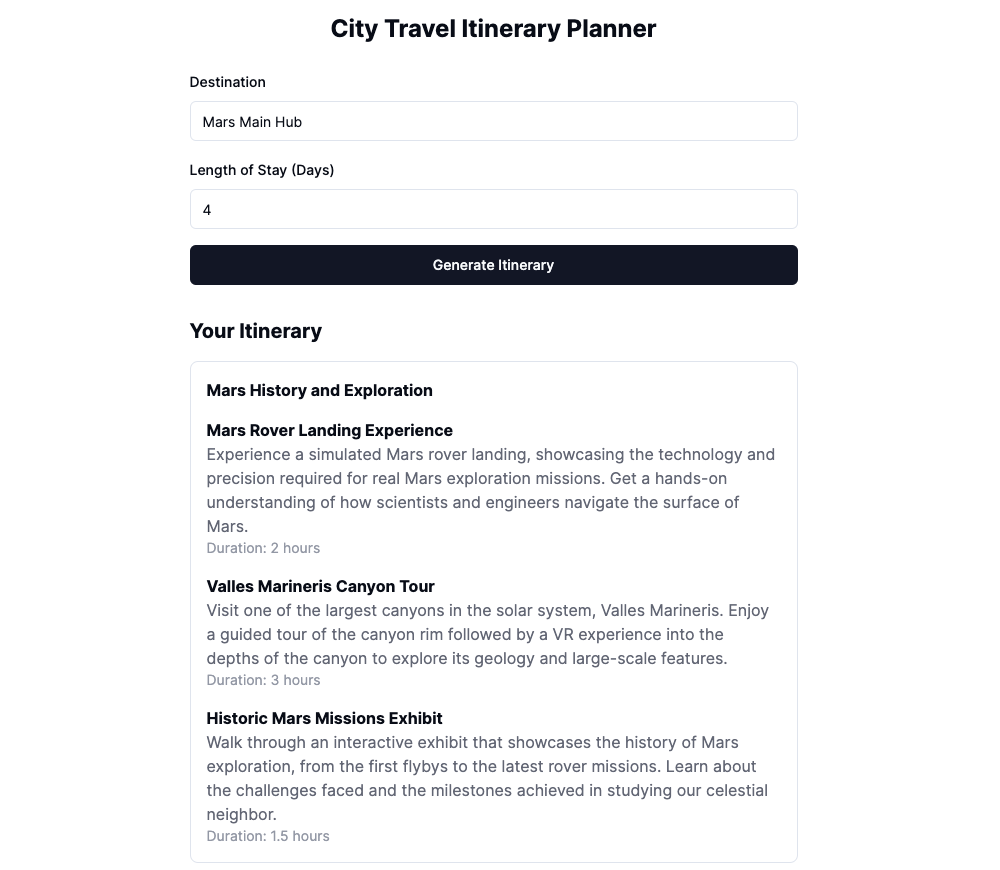
Hallucination of activities for a fictional destination.
You can use additional techniques such as Retrieval Augmented Generation (RAG) if you need more accurate responses.
We have now implemented the API route. Let's move on to the React hook.
React Hook
We use a custom React hook to call the API route and store the activity list as a state. Create a file under src/hooks/use-itinerary.ts with the following content:
import { Itinerary, itinerarySchema } from "@/lib/itinerary-schema";
import { ObjectStreamFromResponse } from "modelfusion";
import { useCallback, useState } from "react";
export function useItinerary() {
const [isGenerating, setIsGenerating] = useState(false);
const [itinerary, setItinerary] = useState<Itinerary>();
const generateItinerary = useCallback(
async ({
destination,
lengthOfStay,
}: {
destination: string;
lengthOfStay: string;
}) => {
setItinerary(undefined);
setIsGenerating(true);
try {
const response = await fetch("/api/stream-objects", {
method: "POST",
body: JSON.stringify({ destination, lengthOfStay }),
});
const stream = ObjectStreamFromResponse({
schema: itinerarySchema,
response,
});
for await (const { partialObject } of stream) {
setItinerary(partialObject);
}
} finally {
setIsGenerating(false);
}
},
[]
);
return {
isGeneratingItinerary: isGenerating,
generateItinerary,
itinerary,
};
}
The hook sets up two state variables: isGenerating and itinerary:
const [isGenerating, setIsGenerating] = useState(false);
const [itinerary, setItinerary] = useState<Itinerary>();
The isGenerating variable can be used to show a loading indicator until the first partial object is received. The itinerary variable contains the generated activity list. It includes partial objects that are received during the generation process.
The main part of the hook is the generateItinerary function:
const generateItinerary = useCallback(
async ({
destination,
lengthOfStay,
}: {
destination: string;
lengthOfStay: string;
}) => {
setItinerary(undefined);
setIsGenerating(true);
try {
const response = await fetch("/api/stream-objects", {
method: "POST",
body: JSON.stringify({ destination, lengthOfStay }),
});
const stream = ObjectStreamFromResponse({
schema: itinerarySchema,
response,
});
for await (const { partialObject } of stream) {
setItinerary(partialObject);
}
} finally {
setIsGenerating(false);
}
},
[]
);
It is wrapped with useCallback to prevent unnecessary re-renders. The function first resets the state variables and then calls the API route with the destination and length of stay.
The response is then passed into ObjectStreamFromResponse, deserializing the content into a simplified object stream. The stream is then incrementally processed, and the partial objects are stored in the itinerary state variable.
Finally, the isGenerating variable is reset to false, even if an error occurs during generation.
The React hook exposes the states and the callback function as isGeneratingItinerary, generateItinerary, and itinerary helpers. Let's use them on the main page.
Itinerary Component
We need a React component to display the activity list. Create a file under src/components/ui/itinerary-view.tsx with the following content:
import { Itinerary } from "@/lib/itinerary-schema";
export const ItineraryView = ({ itinerary }: { itinerary?: Itinerary }) => (
<div className="mt-8">
{itinerary?.days && (
<>
<h2 className="text-xl font-bold mb-4">Your Itinerary</h2>
<div className="space-y-4">
{itinerary.days.map(
(day, index) =>
day && (
<div key={index} className="border rounded-lg p-4">
<h3 className="font-bold">{day.theme ?? ""}</h3>
{day.activities?.map(
(activity, index) =>
activity && (
<div key={index} className="mt-4">
{activity.name && (
<h4 className="font-bold">{activity.name}</h4>
)}
{activity.description && (
<p className="text-gray-500">
{activity.description}
</p>
)}
{activity.duration && (
<p className="text-sm text-gray-400">{`Duration: ${activity.duration} hours`}</p>
)}
</div>
)
)}
</div>
)
)}
</div>
</>
)}
</div>
);
The component takes the activity list as a prop and displays it. It uses Tailwind CSS for styling.
The main difference to typical React components is that it is designed to handle partial data. Most properties and values can be undefined while GPT-4 generates the activity list. For this reason, the component uses optional chaining (?.), nullish coalescence (??), and truthy checks with && in many places.
With the component and the React hook in place, we can now implement the main page.
Main Page
The main page contains the UI controls for the application, the React hook, and the itinerary component. It also uses Tailwind CSS for styling.
Replace the content of src/app/page.tsx with the following code:
"use client";
import { Button } from "@/components/ui/button";
import { Input } from "@/components/ui/input";
import { ItineraryView } from "@/components/ui/itinerary-view";
import { Label } from "@/components/ui/label";
import { useItinerary } from "@/hooks/use-itinerary";
import { useState } from "react";
export default function Main() {
const [destination, setDestination] = useState("");
const [lengthOfStay, setLengthOfStay] = useState("");
const { isGeneratingItinerary, generateItinerary, itinerary } =
useItinerary();
return (
<div className="w-full max-w-2xl mx-auto p-4 md:p-6 lg:p-8">
<h1 className="text-2xl font-bold text-center mb-6">
City Travel Itinerary Planner
</h1>
<form
className="space-y-4"
onSubmit={(e) => {
e.preventDefault();
generateItinerary({ destination, lengthOfStay });
}}
>
<div className="space-y-2">
<Label htmlFor="destination">Destination</Label>
<Input
id="destination"
placeholder="Enter your destination"
required
value={destination}
disabled={isGeneratingItinerary}
onChange={(e) => setDestination(e.target.value)}
/>
</div>
<div className="space-y-2">
<Label htmlFor="length-of-stay">Length of Stay (Days)</Label>
<Input
id="length-of-stay"
placeholder="Enter the length of your stay (up to 7 days)"
required
type="number"
min="1" // Minimum length of stay
max="7" // Maximum length of stay
value={lengthOfStay}
disabled={isGeneratingItinerary}
onChange={(e) => setLengthOfStay(e.target.value)}
/>
</div>
<Button
className="w-full"
type="submit"
disabled={isGeneratingItinerary}
>
Generate Itinerary
</Button>
</form>
<ItineraryView itinerary={itinerary} />
</div>
);
}
The page contains inputs for the destination and the length of stay. Both inputs are linked to state variables.
The useItinerary hook generates the activity list when the form is submitted. It provides the isGeneratingItinerary and itinerary state variables.
The isGeneratingItinerary variable is used to turn off the form and the button while the activity list is being generated. The itinerary variable is passed into the ItineraryView component.
6. Running The Application
You can now run the application with the following command:
npm run dev
The application will be available at http://localhost:3000. You can enter a destination and the length of your stay and click the "Generate Itinerary" button to generate the activity list.
7. Conclusion
In this tutorial, we built a travel planner application using Next.js, GPT-4, and ModelFusion. This application shows how to generate and stream structured data from GPT-4 to a web browser. It also demonstrates how to display this data using React components.
You can apply this method to develop various applications. These applications can generate and send structured information from large AI models. It's a new way to use AI outputs in user interfaces. If you want to explore more, experiment with the code. Happy coding!